Pourquoi la CI/CD est devenue une question cyber en 2026
Il y a cinq ans, un pipeline CI c'était : lint + test unitaire + build. C'était largement suffisant parce que le code était écrit lentement, relu par des pairs, et passait par plusieurs cerveaux avant la production.
Ce modèle ne tient plus. Trois changements rendent la CI cyber-first indispensable :
1. Le volume de code généré par IA explose
Claude Code, GitHub Copilot, Codex et Cursor génèrent aujourd'hui des milliers de lignes par jour dans un projet moyen. Un développeur peut merger 10x plus de code qu'il y a deux ans. Les humains n'ont plus la bande passante pour tout relire en profondeur. Votre CI doit compenser cette dette d'attention.
2. Les agents IA commettent des erreurs de sécurité spécifiques
Les LLMs ont été entraînés sur du code historique, souvent vulnérable. Ils reproduisent des patterns dangereux : SQL injection, hardcoded secrets, chemins sans sanitisation, régex vulnérables au ReDoS. Le rapport Snyk 2026 AI Code Security (ouvre un nouvel onglet) (et l'étude Purdue 2023 (ouvre un nouvel onglet) avant lui) montrent que 30 à 50% du code généré par IA contient au moins une faiblesse connue. Sans scan automatique, ces vulnérabilités passent.
3. La démocratisation = plus de non-experts aux commandes
Des entrepreneurs, designers, PM, étudiants écrivent et déploient du code en 2026. Ils ne connaissent pas forcément OWASP Top 10, ni la différence entre innerHTML et textContent. La CI doit leur être le garde-fou qu'ils n'ont pas dans leur formation.
À quoi ressemble concrètement une CI cyber-first
Avant d'entrer dans les détails, voici un exemple de workflow CI complet tel qu'il tourne sur un projet de prod en 2026. Chaque nœud est une étape indépendante qui peut bloquer le merge.
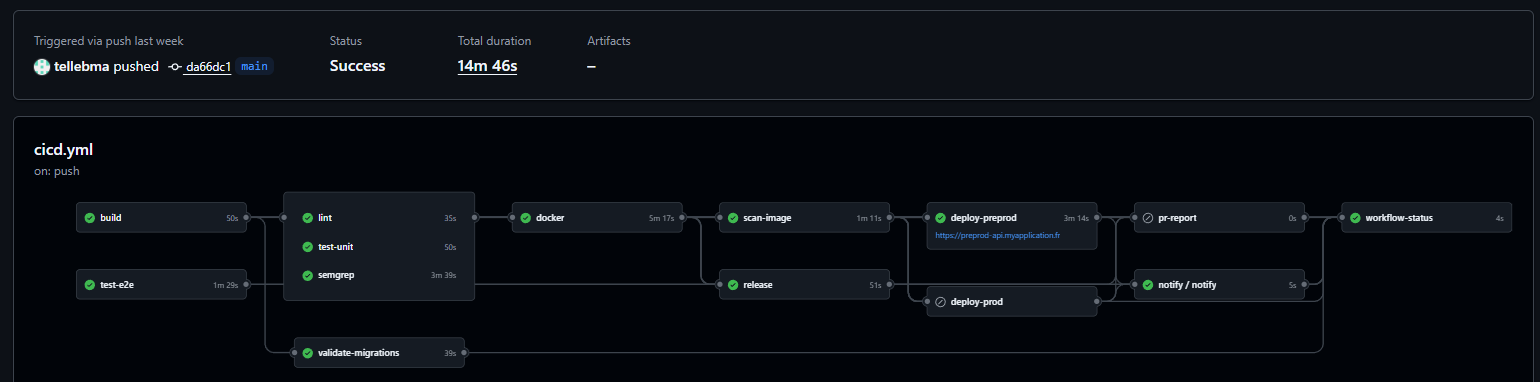
On y voit l'enchaînement typique : build et tests en parallèle, puis lint + scan Semgrep, construction de l'image Docker, scan de l'image, release, et deploy preprod avant prod. Les boxes en vert sont les étapes qui tournent à chaque push. Une seule qui échoue stoppe la chaîne. 14 minutes pour tout, c'est un coût tout à fait raisonnable pour avoir ce niveau de filet.
L'anatomie d'une CI cyber-first en 2026
Une CI moderne doit enchaîner huit couches de vérification, dans cet ordre, en fail-fast :
1. Lint + formatage → cohérence de style
2. Type-check → erreurs de type à la compilation
3. Tests unitaires → logique métier
4. Tests d'intégration → interactions composants
5. SAST (Static App Security) → vulnérabilités dans le code source
6. SCA (Software Composition Analysis) → vulnérabilités dans les dépendances
7. Secret scanning → secrets accidentellement committés
8. IaC + Dockerfile security → infrastructure as code + conteneurs
À cela s'ajoutent deux couches périodiques (pas à chaque PR mais hebdomadaires) :
9. DAST (Dynamic App Security) → tests contre l'app qui tourne
10. Pen test automatisé / fuzzing → découverte active de failles
Les outils concrets par couche
| Couche | Outils open-source ou freemium |
|---|---|
| Lint | ESLint, Biome, Prettier, Ruff (Python), golangci-lint |
| SAST | Semgrep (ouvre un nouvel onglet) (gratuit pour l'OSS), CodeQL (ouvre un nouvel onglet) (GitHub natif), SonarCloud |
| SCA | Dependabot (ouvre un nouvel onglet), Snyk (ouvre un nouvel onglet), OSV-Scanner (ouvre un nouvel onglet) |
| Secret scanning | gitleaks (ouvre un nouvel onglet), trufflehog (ouvre un nouvel onglet), git-secrets |
| IaC scan | Checkov (ouvre un nouvel onglet), Trivy (ouvre un nouvel onglet), tfsec (ouvre un nouvel onglet) |
| Docker scan | Trivy (ouvre un nouvel onglet), Snyk Container, Grype (ouvre un nouvel onglet) |
| DAST | OWASP ZAP (ouvre un nouvel onglet), Nuclei (ouvre un nouvel onglet) |
| Fuzzing | OSS-Fuzz (ouvre un nouvel onglet), cargo-fuzz, go-fuzz |
Tous existent en version gratuite ou gratuite-pour-OSS. Aucune excuse budgétaire pour ne pas les activer sur un projet perso ou une startup.
Red Team, Blue Team, Purple Team : comprendre le modèle
La cybersécurité mature ne se fait pas en solo. Elle repose sur trois rôles qui se complètent, hérités du monde militaire puis adaptés au cyber.
🔴 Red Team : "je casse"
Les Red Teamers simulent une attaque réaliste. Leur job est de trouver comment entrer dans votre système en pensant comme un attaquant. Ils combinent OSINT (renseignement), exploitation de vulns, phishing, escalade de privilèges.
Exemples de livrables Red Team :
- Rapport de pentest avec CVE custom trouvées
- Chaîne d'exploitation complète (de la faille XSS au RCE prod)
- PoC (proof of concept) exploitable
- Évaluation de la posture humaine (social engineering)
Outils typiques : Metasploit, Burp Suite, Nmap, Cobalt Strike, Bloodhound.
🔵 Blue Team : "je défends"
Les Blue Teamers construisent et maintiennent les défenses. Leur job est de détecter, bloquer, responder aux attaques. Ils gèrent le SOC (Security Operations Center), configurent les SIEM, analysent les logs.
Exemples de livrables Blue Team :
- Playbooks d'incident response
- Règles de détection custom (YARA, Sigma, Falco)
- Alerting et SLO de détection
- Hardening des serveurs et configs
Outils typiques : Splunk, ELK/Wazuh, Sigma rules, CrowdStrike, Falco.
🟣 Purple Team : "je fais dialoguer les deux"
La Purple Team n'est pas un rôle séparé, c'est une méthode de collaboration. Red et Blue travaillent ensemble pour : Red attaque → Blue doit détecter → ils identifient les angles morts → Blue ajoute la détection → Red invente une variante → itération.
C'est le modèle le plus efficace en 2026, surtout dans les équipes où on ne peut pas se payer deux équipes distinctes. Vous faites du Purple Teaming vous-même avec des outils comme Caldera (ouvre un nouvel onglet) (MITRE ATT&CK automatisé) ou Atomic Red Team (ouvre un nouvel onglet).
Ce qu'il faut intégrer dans votre CI en mode Purple Team
Même en solo ou en startup, vous pouvez faire du Purple Teaming light via votre CI. Voici comment.
🔴 Côté Red (offensif automatisé)
- Semgrep avec les règles OWASP Top 10 à chaque PR : c'est votre Red Teamer automatique qui cherche les patterns vulnérables
- Nuclei avec des templates contre votre environnement de staging (hebdomadaire ou nightly)
- Fuzzing sur les endpoints critiques : un générateur envoie 10 000 inputs bizarres, votre code doit tenir
- Tests de régression sur les CVE passées : chaque CVE que vous avez fixée doit avoir un test qui échoue si la régression revient
🔵 Côté Blue (défensif automatisé)
- Logs structurés obligatoires : chaque requête HTTP, chaque appel DB, chaque appel IA (!) est logué avec un trace ID
- Détection d'anomalies en prod : Sentry, Datadog ou un SIEM open-source comme Wazuh alertent sur des patterns inhabituels
- WAF activé par défaut : Cloudflare en gratuit, ou ModSecurity si self-hosted
- Fail2ban ou équivalent : sur vos VPS, bloque automatiquement les scans et brute force
🟣 Intégration CI/CD avec feedback loop
# Exemple GitHub Actions : CI cyber-first minimalename: security-cion: [pull_request]jobs:security:runs-on: ubuntu-lateststeps:# 1. Semgrep SAST- uses: semgrep/semgrep-action@v1with:config: p/owasp-top-ten# 2. Gitleaks secret scanning- uses: gitleaks/gitleaks-action@v2# 3. Trivy pour Dockerfile + deps- uses: aquasecurity/trivy-action@masterwith:scan-type: fsscan-ref: .# 4. OSV-Scanner pour deps- uses: google/osv-scanner-action@v1with:scan-args: --recursive ./# 5. Tests unitaires + intégration- run: npm ci && npm test# 6. Gate : bloque le merge si une vuln critique est trouvée- name: Fail on criticalif: failure()run: exit 1
Cette CI prend 3 à 8 minutes par PR. Ça paraît long ? C'est infiniment moins que gérer une fuite de données.
Un exemple de production réel : CI enchaînée et orchestrée
La CI minimale plus haut est un bon point de départ. Voici un exemple plus mature qui tourne en production, orchestré autour de NestJS + Prisma + Postgres + Docker. Il illustre plusieurs techniques qui valent le détour : path filters, concurrency avec annulation, déclencheurs conditionnels, déploiement preprod/prod séparé par tag, rapport PR automatique.
Structure globale du pipeline
build (50s)
├── lint (35s)
├── test-unit (50s)
├── test-e2e (1m29s, conditionnel)
├── validate-migrations (39s)
├── semgrep (3m39s, SAST)
├── docker (5m17s, build + push)
│ └── scan-image (1m11s, Trivy)
│ ├── deploy-preprod (3m14s)
│ └── deploy-prod (sur tag vX.Y.Z)
├── release (semantic-release auto-tag)
├── pr-report (commentaire sur PR)
├── notify (Discord webhook post-deploy)
└── workflow-status (gate final)
Durée totale : ~14 min pour un push complet avec deploy preprod. C'est le budget à viser pour un projet sérieux.
Le déclenchement intelligent
on:push:branches: [ "main" ]tags: [ "v*" ] # Format: vXX.YY.ZZpull_request:paths-ignore:- '**.md'- 'docs/**'- '.gitignore'- 'LICENSE'pull_request_review:types: [submitted]issue_comment:types: [created]workflow_dispatch:concurrency:group: ${{ github.workflow }}-${{ github.ref }}cancel-in-progress: truepermissions: {}
Trois points à noter :
paths-ignoreévite de lancer le full pipeline pour un changement de README. Ça économise plusieurs minutes de CI par jour.concurrencyaveccancel-in-progressannule les runs obsolètes quand un nouveau commit arrive sur la même branche. Pas de queue qui s'accumule.permissions: {}au niveau workflow = principe du moindre privilège. Chaque job redemande explicitement les permissions dont il a besoin (contents: read,packages: write, etc.). Une pratique DevSecOps standard qu'on néglige trop souvent.
Jobs lents conditionnels : e2e sur demande
Les tests E2E durent 1m30s. Les lancer sur chaque push de PR ralentit tout sans grand bénéfice pendant l'itération. La solution :
test-e2e:runs-on: ubuntu-latestif: |(github.event_name == 'push') ||(github.event_name == 'pull_request_review' && github.event.review.state == 'approved') ||(github.event_name == 'issue_comment' && github.event.issue.pull_request != null && github.event.comment.body == '/run-e2e') ||(github.event_name == 'workflow_dispatch')
E2E se lance uniquement :
- Sur push direct vers
main(filet de sécurité post-merge) - Sur approbation de PR (dernière validation avant merge)
- Sur commentaire
/run-e2edans une PR (déclenchement manuel) - En workflow dispatch (manuel)
Résultat : PRs rapides pendant l'itération, validation complète au moment-clé. C'est une forme de Chaos Engineering light : le pipeline adapte sa profondeur au contexte.
Services éphémères Postgres pour les tests
Un des problèmes récurrents : les tests unitaires qui touchent la DB ont besoin d'une vraie Postgres, pas de mocks. GitHub Actions permet de lancer des services Docker à la volée :
services:postgres:image: postgres:17-alpineenv:POSTGRES_USER: testuserPOSTGRES_PASSWORD: testpassPOSTGRES_DB: testdboptions: >---health-cmd pg_isready--health-interval 10s--health-timeout 5s--health-retries 5ports:- 5432:5432
La DB tourne, les tests tapent dedans, ça se jette à la fin du job. Aucun secret à gérer, aucune DB partagée contaminée entre les runs. C'est l'équivalent d'un environnement de test hermétique, gratuit, reproductible.
Validation des migrations avant deploy
Un job dédié validate-migrations s'assure que les migrations Prisma sont cohérentes, même avec une shadow database :
- name: Validate Prisma migrationsenv:DATABASE_URL: postgresql://migration_test:migration_test@localhost:5433/testdb_migrationrun: |set -euo pipefailnpx prisma migrate deploynpx prisma migrate diff \--from-schema-datamodel prisma/schema.prisma \--to-migrations prisma/migrations \--shadow-database-url "postgresql://migration_test:migration_test@localhost:5433/shadow_db" \--exit-code
Ça attrape les migrations qui compilent mais divergent du schéma (oubli de prisma migrate dev), ou celles qui casseraient la DB au déploiement. Cette vérification seule a sauvé plusieurs deploys en prod dans un projet réel.
Scan image avec Trivy en SARIF
Une fois l'image Docker construite, elle passe à Trivy pour détecter les CVE des couches :
# SECURITY: Trivy a été compromis dans une attaque de supply chain (mars 2026).# Seul le SHA 57a97c7 (v0.35.0) est vérifié safe. NE PAS mettre à jour sans vérification.- name: Run Trivy vulnerability scanner (SARIF)uses: aquasecurity/trivy-action@57a97c7e7821a5776cebc9bb87c984fa69cba8f1 # v0.35.0 (verified safe)with:image-ref: ${{ needs.docker.outputs.image-tag }}format: sarifoutput: trivy-results.sarifseverity: CRITICAL,HIGH- name: Upload Trivy scan resultsuses: github/codeql-action/upload-sarif@ff0a06e83cb2de871e5a09832bc6a81e7276941f # v3.28.18with:sarif_file: trivy-results.sarif
Deux choses critiques ici :
- Pin SHA obligatoire sur les actions sensibles. Le commentaire expliqué que Trivy a été compromis dans une attaque supply chain en mars 2026. Seul un SHA vérifié safe est autorisé.
@latestou@v0serait une porte ouverte. - Format SARIF uploadé à GitHub Security tab. Les CVE trouvées apparaissent dans l'onglet Security du repo, corrélées aux alertes Dependabot. Un seul endroit pour voir toute la posture sécurité.
Déploiement par environnement avec approbations
deploy-preprod:environment:name: preprodurl: https://preprod-api.example.comif: |(github.ref == 'refs/heads/main' ||(github.event_name == 'pull_request' && contains(github.event.pull_request.title, '[DEPLOY]'))) &&needs.build.result == 'success' &&needs.lint.result == 'success' &&needs.test-unit.result == 'success' &&needs.semgrep.result == 'success' &&needs.docker.result == 'success' &&needs.scan-image.result == 'success'deploy-prod:environment:name: productionurl: https://api.example.comif: startsWith(github.ref, 'refs/tags/v') # tag vX.Y.Z uniquement
Deux mécanismes de garde-fou combinés :
- GitHub Environments : une approbation manuelle est exigée avant le deploy prod (configurable via l'UI). Même si le workflow se déclenche, il attend qu'un humain valide.
- Dépendances explicites : le deploy prod ne peut démarrer que si tous les jobs amont sont passés. Aucun shortcut "je push et je deploy sans test".
Rapport PR automatique
Après chaque run sur une PR, un commentaire résume tout le pipeline dans la PR elle-même :
pr-report:needs: [build, lint, test-unit, test-e2e, semgrep, docker, scan-image, deploy-preprod, deploy-prod]if: always() && (github.event_name == 'pull_request' || ...)steps:- name: Générer le rapport de PRrun: ./.github/scripts/generate-pr-report.sh- name: Comment PRrun: node ./.github/scripts/publish-pr-comment.cjs
Avec if: always(), le rapport tourne même si des jobs amont ont échoué. Le reviewer voit en un coup d'œil : build vert, tests unitaires verts, semgrep trouve 2 findings, deploy preprod OK. Gain énorme en friction de review.
Notification Discord post-deploy
notify:if: always() && (needs.deploy-preprod.result != 'skipped' || needs.deploy-prod.result != 'skipped')uses: ./.github/workflows/discord-notify.ymlwith:environment: ${{ needs.deploy-prod.result != 'skipped' && 'PRODUCTION' || 'PREPROD' }}status: ${{ needs.deploy-prod.result != 'skipped' && needs.deploy-prod.result || needs.deploy-preprod.result }}url: ${{ needs.deploy-prod.result != 'skipped' && 'https://api.example.com' || 'https://preprod-api.example.com' }}
L'équipe est prévenue dès qu'un deploy part (succès ou échec). Côté Blue Team, c'est le premier signal pour vérifier que rien n'est cassé. C'est aussi un audit trail immédiat.
Workflow-status : le gate final
workflow-status:needs: [build, lint, test-unit, test-e2e, validate-migrations, semgrep, docker, scan-image, ...]if: always()steps:- name: Check workflow statusrun: |if [[ "$BUILD_RESULT" == "failure" ]]; then exit 1; fiif [[ "$LINT_RESULT" == "failure" ]]; then exit 1; fiif [[ "$TEST_UNIT_RESULT" == "failure" ]]; then exit 1; fiif [[ "$SEMGREP_RESULT" == "failure" ]]; then exit 1; fiif [[ "$DOCKER_RESULT" == "failure" ]]; then exit 1; fi# E2E conditionnel : OK d'être skippedif [[ "$TEST_E2E_RESULT" == "failure" ]]; then exit 1; fiecho "All critical jobs succeeded"
Un job final qui consolide tout. Son statut est le required status check sur la branche protégée main : impossible de merger si ce job est rouge. Tous les gates en un seul endroit.
Les erreurs classiques à ne pas faire
❌ Avoir une CI qui "passe toujours"
Si votre CI est verte depuis 3 mois sans jamais alerter, ce n'est pas qu'elle marche. C'est qu'elle ne teste rien. Forcer un fail volontaire de temps en temps pour valider que les gates marchent.
❌ Désactiver Dependabot parce que "trop de PRs"
Les alertes Dependabot qui vous saoulent sont la preuve que votre stack a de la dette de sécurité. La solution n'est pas de désactiver, c'est de merger les updates patch/minor automatiquement (via automerge (ouvre un nouvel onglet) avec validation CI).
❌ Faire du security scanning après le déploiement
Une vulnérabilité détectée en prod, même fixée en 2 heures, a déjà été exposée pendant 2 heures. Le scan doit être avant le merge, pas après.
❌ Copier-coller des règles Semgrep sans les comprendre
Les faux positifs vous font désactiver les règles, et au bout de 3 mois la suite est cassée. Prenez le temps de comprendre chaque règle, marquez les exclusions explicitement avec un commentaire // nosemgrep: rule-id — reason.
❌ Ignorer la chaîne d'approvisionnement
npm install télécharge 1000 packages transitifs. Un seul maintenu par un compte compromis peut injecter un malware. Les scans SCA ne suffisent pas : vous devez aussi pinner les versions (lockfile) et envisager un registry privé (Verdaccio, Artifactory) qui cache les packages.
Plan d'action pour les 4 prochaines semaines
Semaine 1 : activation des bases (0 € de budget)
- Dependabot activé sur tous les repos GitHub (gratuit)
- Gitleaks en pre-commit ET en CI
- Semgrep avec le pack
p/owasp-top-tendans CI - OSV-Scanner sur les deps à chaque PR
-
.gitignore+.dockerignorerelus et complétés pour les patterns sensibles
Semaine 2 : hardening infrastructure
- Trivy scan du Dockerfile + image finale
- Checkov sur tous les fichiers
docker-compose.yml, Terraform, Kubernetes - WAF Cloudflare activé (gratuit jusqu'à un certain volume)
- Headers de sécurité : CSP, HSTS, X-Frame-Options, Referrer-Policy
Semaine 3 : détection et observabilité
- Logs structurés partout (JSON, pas du texte brut)
- Sentry ou équivalent sur le frontend ET backend
- Alerting sur patterns suspects (spike de 500, auth echec répétés)
- Monitoring des secrets exposés sur GitHub (alerte automatique via Secret Scanning)
Semaine 4 : Purple Teaming léger
- Installer Caldera (ouvre un nouvel onglet) ou Atomic Red Team (ouvre un nouvel onglet) en lab isolé
- Jouer 3 scénarios ATT&CK simples (exfiltration, persistence, lateral movement)
- Vérifier que vos logs/alerting détectent les 3 scénarios
- Documenter les angles morts pour les combler en semaine 5+
Les signaux que votre CI cyber fonctionne
Quand la CI cyber est bien calibrée, vous observez :
- Au moins une alerte par mois sur une vuln de dep transitive (= votre scanner marche)
- Faux positifs < 10% en SAST (= vos règles sont calibrées)
- Aucun secret n'arrive dans l'historique Git (= gitleaks + git-secrets fonctionnent)
- Les devs râlent parfois parce que la CI bloque leur PR (= la CI fait son job)
- MTTD (Mean Time To Detect) < 1 jour sur les incidents prod (= votre Blue side détecte vite)
- Aucune CVE critique publiée sur votre stack n'a plus de 7 jours sans fix mergé (= votre process patch management tourne)
Si tout est trop silencieux, vérifiez d'abord que la CI teste vraiment quelque chose. Le silence en cybersécurité est presque toujours un mauvais signe.
Les agents IA changent la donne, autant s'en servir
En 2026, la cyber peut elle-même bénéficier des agents IA. Pas pour remplacer les humains, mais pour industrialiser ce qui est répétitif :
- Triage automatique des alertes Dependabot : un agent lit la CVE, évalue l'exposition réelle (est-ce que cette fonction est utilisée ?), propose un PR d'upgrade avec tests
- Review sécurité de PR : un agent commente les PRs avec les risques OWASP détectés avant même que l'humain touche
- Fuzzing intelligent : un agent génère des inputs adversariaux en fonction du code (bien plus efficace qu'un fuzzer random)
- Génération de détections Sigma/YARA : à partir d'un nouvel IoC, un agent écrit la règle de détection
Claude Code est particulièrement bien placé pour ces usages parce qu'il comprend votre codebase, pas seulement un fichier isolé. Voir le Skill security-review pour un exemple concret.
Pour aller plus loin
- Clé API Anthropic fuitée ? Plan d'action en 5 étapes — post-incident en urgence
- Ne jamais donner de clés API à Claude Code — prévention primaire
- Sécurité des MCP — le nouveau vecteur d'attaque via les connecteurs IA
- Permissions et sandbox Claude Code — cloisonnement local
- OWASP Top 10 2021 (ouvre un nouvel onglet) — référence à relire chaque année
- MITRE ATT&CK (ouvre un nouvel onglet) — taxonomie des tactiques d'attaque
- CISA KEV Catalog (ouvre un nouvel onglet) — les vulns activement exploitées, priorité absolue